:format(webp))
Vector Databases and Their Connection to AI
In the realm of data storage, a vector database stands as a distinct type of database that specializes in storing data in the form of high-dimensional vectors. These vectors serve as mathematical representations of features or attributes, encompassing a specific number of dimensions. Depending on the intricacy and level of detail within the data, the dimensions of the vectors can vary from tens to thousands. Typically, these vectors are derived by subjecting the raw data, including text, images, audio, and video, to various transformation or embedding functions. These functions can leverage diverse methods like machine learning models, word embeddings, or feature extraction algorithms to generate meaningful vector representations.
 Pinecone Vector DB visualization. [Source: www.pinecone.io]
Pinecone Vector DB visualization. [Source: www.pinecone.io]
Pinecone DB is a powerful Vector DB that excels at similarity search and nearest neighbor retrieval. It is designed to handle vast amounts of high-dimensional data, making it ideal for AI applications. By leveraging advanced indexing and search algorithms, Pinecone DB enables lightning-fast retrieval of similar vectors, greatly enhancing the efficiency and accuracy of AI systems.
So, how are Vector DBs, including Pinecone DB, useful in the field of AI? There are many answers to that question, but in our case, we took advantage of the long-term memory that these databases can provide to the AI models. Long-term memory enables them to retain information and make connections over extended periods. Vector DBs play a crucial role in facilitating long-term memory by providing efficient storage and retrieval of high-dimensional vectors.
Langchain: Combining Vector DBs with Language Models
Langchain emerges as a powerful tool that harnesses the synergy between Vector DBs and language models. It acts as a framework facilitating efficient encoding and retrieval of text data through Vector DBs. By transforming text into vector representations, Langchain enables a wide range of functionalities including semantic search, information retrieval, and even multilingual applications. Its capabilities empower AI systems to process and analyze textual data with enhanced accuracy and speed, opening doors to more advanced language-based applications.
Data Ingestion into Pinecone DB via Storyblok
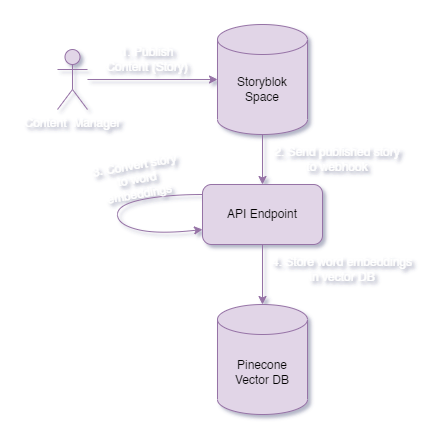
Storyblok: A Headless Content Management System (CMS)
In case you’re unfamiliar, Storyblok is a headless content management system (CMS) that enables users to create and manage content for websites and applications. It provides a flexible and intuitive interface for content creation and editing, allowing non-technical users to contribute to the content development process. With Storyblok, content can be structured into reusable blocks, making it easy to maintain consistency across multiple pages and platforms. By separating the content from the presentation layer, Storyblok empowers developers to build dynamic and personalized digital experiences across different devices and channels.
Ingestion Process Flow
We utilize Storyblok's "Story published & unpublished" webhook to ingest story data into Pinecone DB. This webhook triggers an endpoint whenever a story is published, providing relevant information about the story.
const PINECONE_INDEX_NAME = 'my-index';
const PINECONE_ENVIRONMENT = 'asia-southeast1-gcp-free';
const PINECONE_API_KEY = 'xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx';
export const pineconeIngestData = async (
storyText: string,
storyName: string
) => {
// Split text into chunks
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
chunkOverlap: 200,
});
const docs = await textSplitter.splitDocuments([
new Document({ pageContent: storyText }),
]);
const embeddings = new OpenAIEmbeddings();
// Create and initialize Pinceone client instance
const pinecone = new PineconeClient();
await pinecone.init({
environment: PINECONE_ENVIRONMENT,
apiKey: PINECONE_API_KEY,
});
const pineconeIndex = pinecone.Index(PINECONE_INDEX_NAME);
// Convert documents into vector values
const vectorValues = await embeddings.embedDocuments(
docs.map((doc) => doc.pageContent)
);
// Create vector with metadata.text being equal to the content we want to store
const vectors: Vector[] = vectorValues.map((vector, index) => ({
id: storyName + index,
values: vector,
metadata: { text: docs[index].pageContent },
}));
// Here we upsert data into the Pinecone DB
pineconeIndex.upsert({
upsertRequest: {
vectors: vectors,
namespace: 'my-namespace',
},
});
};
The data ingestion process follows these steps:
The
/api/storyblok-publishendpoint is called, passing an object as the request body. This object contains details such as the text, action (e.g., published), space ID, story ID, and full slug.The story is fetched using the provided
story_id.The story data is converted into a string (
storyText).The string is passed to the
splitDocumentsmethod, called on theRecursiveCharacterTextSplitterinstance provided by Langchain. This method splits the string into smaller "documents."The chunks are embedded as
vectorValuesand converted intovectorsfor upserting into the Pinecone vector database.
Retrieval of Data in the Chatbot
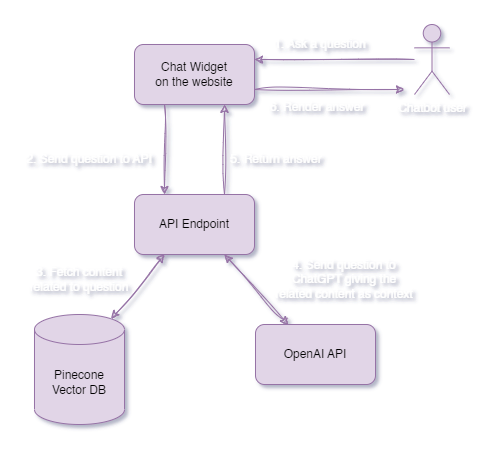
To incorporate the long-term memory feature with vector databases into our Chatbot, we made a few additions and refinements to the existing setup.
const OPENAI_API_KEY= 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
const PINECONE_INDEX_NAME = 'my-index';
const PINECONE_ENVIRONMENT = 'asia-southeast1-gcp-free';
const PINECONE_API_KEY = 'xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx';
// Init our openAI api client
const configuration = new Configuration({
apiKey: OPENAI_API_KEY,
});
const openAiApi = new OpenAIApi(new Configuration(configuration));
// Init our Pinecone client
const pinecone = new PineconeClient();
await pinecone.init({
environment: PINECONE_ENVIRONMENT,
apiKey: PINECONE_API_KEY,
});
const pineconeIndex = pinecone.Index(PINECONE_INDEX_NAME);
const embeddings = new OpenAIEmbeddings({});
const vectorStore = await PineconeStore.fromExistingIndex(embeddings, {
pineconeIndex,
textKey: 'text',
namespace: 'makersden',
});
// Query for the three most similar documents
const docs = await vectorStore.similaritySearch(sanitizedPrompt, 3);
const docsAsHistory: Dialogue[] = docs.map((doc) => ({
role: 'system',
content: doc.pageContent,
}));
// Feed your docs as dialogue history to ChatGPT (via LangChain)
Here's an overview of the process:
An instance of
OpenAIApiandPineconeClientis created, and configured with the necessary parameters.The Pinecone index is retrieved using the specified index name.
OpenAI embeddings and a
PineconeStoreare created to enable similarity search.The Chatbot's context is enriched with the retrieved documents, stored as
docsAsHistory.
Summary
The combination of Vector DBs and content management systems greatly enhances the accuracy of responses a Large Language Model can give to your customers. By leveraging the power of long-term memory and advanced indexing and search algorithms, these technologies enable dynamic and engaging conversations in chatbots. The data ingestion and retrieval process can be streamlined by using webhooks and Langchain's efficient encoding and retrieval of text data, while Pinecone DB provides a powerful Vector DB for similarity search and nearest neighbor retrieval.
:format(webp))
:format(webp))
:format(webp))